漫談高可用性與災難重建的規劃與評估(第三集)
屠立剛 Joseph Tu
- 精誠資訊/恆逸教育訓練中心-資深講師
- 技術分類:網路管理與通訊應用
前言
我們經常會聽到對於系統的「可用性/Availability」評估,尤其是現今最熱門的IT資訊系統的虛擬化與雲端化架構,是目前全球探討系統評估中,最流行且最熱門的話題。
在前面的第一集與第二集中,討論了系統運作評估的基本概念,接下來本集要來探討「持續運作/Continuity Operation」與「災難重建/Disaster Recovery」的基本概念。
在討論這個主題之前,我們先來看一下以下的圖片,您可以先觀察此張圖所看到的內容並進行思考,是否能對此圖的各項內容進行解釋。
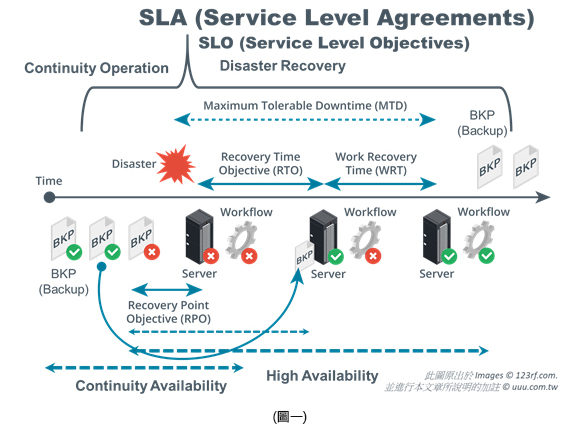
「服務水準協議/Service Level Agreements/SLA」
以上這張圖的一開始便說明了這整個系統所提供的使用程序可以用一個SLA來代表,那麼什麼是SLA呢?
SLA完整的名稱為「服務水準協議/Service Level Agreements」,這代表了提供「商品/系統」的「供應商/Provider」對「消費者/Consumer」在購買後,能提供使用該「商品/系統」服務水準的正式承諾。
但除此之外,為了能夠更清楚的說明SLA,因此通常在SLA下,會附帶說明其水準服務的目標,又稱為「服務水準目標/Service Level Objectives/SLO」。例如:我們經常聽到的這個產品在您完成購買後,我們對該產品提供保固一年的服務,這就是所謂的SLA,在保固期間中,如果該產品在自然使用情況下有損壞的話,我們會負責進行免費的維修服務,這就是所謂的SLO。
所以,對於SLA/SLO內容的了解,不管是供應商或是消費者,都應該要有基本的認識與了解,如此才能夠在構成使用「商品/系統」成案時,可以建立雙方所需要的共識。通常在使用價值越高或越複雜的「商品/系統」時,會越重視SLA的存在,除此之外,近年來,由於在網際網路上雲端服務的興起,因為虛擬化的關係,在看不到實體執行環境下,也更重視雲端服務所提供的SLA。
「最大可容忍停機時間/ Maximum Tolerable Downtime/MTD」
通常有提供SLA的供應商,都會提供類似像圖二的一張表,來說明所提供「可用性/Availability」的等級,其中這項等級通常會採用以比率性來說明所提供服務的等級。 而在此比率等級中,對「消費者」在使用上有最大影響的便是MTD,請參考上圖,也就是必須容忍系統無法運作的最大時間。
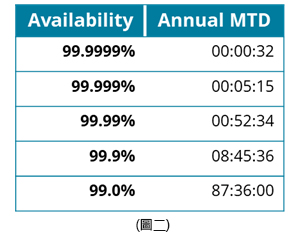
MTD的全名是「Maximum Tolerable Downtime/最大可容忍停機時間」,通常會對其「可用性」的百分比,採用「年/月」的平均來換算系統可允許停止服務的時間,例如:在上表中,99.0%可用性的年平均MTD是87小時36分鐘,是經過下面的算式計算出來的:
24*365*60=525600 ⭢ 525600*1%=5256 ⭢ 5256/60=87.6 ⭢ 87:36:00 ⭢ 3:15:36:00。
表示99%的SLA提供停止服務的最大容忍時間是3天15個小時36分鐘。
從上圖可以看到MTD所指的是從災難發生導致服務無法提供時,開始進行「災難重建」的程序,在此階段的時程是停止「消費者」的使用與服務。
MTD所包含的主要程序還可以分兩大部分:「RTO/Recovery Time Objective」與「WRT/Work Recovery Time」,由此可以看到對系統提供服務的能力,第一部份的RTO指的是提供重建系統到可進行基礎架構執行的部分,而第二部分則是提供重建系統恢復到可開始執行運作的部分。
但不管如何,對於上述說明由供應商所提供的SLA等級,即使是最高等級,都代表了會產生損失,即使完成了災難重建的程序後,也無法完全恢復到災難發生前的執行狀態,也就是說,當災難一旦發生後,便會開始產生災難損失。 所以「災難重建/Disaster Recovery」評估規劃的目的是讓系統作業可以在災難發生後,還可以將該系統恢復到能繼續提供執行服務的能力。
「重建時程目標/RTO/Recovery Time Objective」
當系統發生災難導致無法提供系統服務後,開始進行重建系統基礎架構目標程序所需要花費的時程,稱為RTO。
對於重建系統基礎架構目標程序所花費的時間大小與在持續運作期間,對系統進行基礎架構備援作業(例如:系統備份作業)的執行有非常大的關係。
RTO的最大時間就是重建系統基礎架構的時間,也就是如果在持續運作的時段中,沒有進行任何系統基礎架構的持續備援作業的執行,則在災難發生後,所要執行的RTO,便是重新建立該系統的基礎架構。
例如:當您所使用的電腦環境,沒有進行任何備份作業的情況下,該電腦損壞了,如果您需要繼續使用此電腦環境,您也只能重新建立所使用電腦的基礎環境,但即使您重新建立好需要使用的電腦環境後,在電腦環境中的資料還是損失了。
因此,在此要知道,要減少執行RTO程序時間的前置條件是對該系統在「持續運作/Continuity Operations」階段,有提供持續性的重建系統備援程序(例如:持續性的備份作業),這也就是為什麼我們在談「災難重建」的最基本作業條件是「備份作業」,而且要是一個具有週期性的持續性備份作業。
「作業重建時間/WRT/Work Recovery Time」
由於在完成災難重建的RTO程序後,所代表的是將系統恢復到基本架構可執行的能力,但並不是代表系統已經恢復到可銜接災難執行發生前,可正常工作的環境,因此WRT是代表在完成PTO基本重建程序後,重建能夠銜接到災難發生前的工作執行環境的最大能力,例如:檢查回存資料數據的完整性,包括了資料庫與資料日誌的完整以及在災難發生後,殘餘可進行修補與回復的資料檔案與可以從資料日誌中修復的資料內容。
在網路上有許多有關災難重建的相關文章中,說明了WRT是可以忽略的,尤其是當系統所進行的持續性備份作業在很完整的情況下所進行的災難重建程序,在完成RTO作業程序後,WRT的作業程序就會變得很短,因此有人便穿鑿附會的說明MTD就是ROT,而忽略WRT,這樣是對的嗎?
其實對於在災難重建作業中,是否要評估WRT的規劃,取決的重點是在無法透過RTO重建程序所產生災損內容的重要性。
要說明WRT的重要性評估,要先從圖一的內容來看,如果我們細分災難發生的情況,有時最嚴重的停止運作的災難並不是瞬間發生的,或在發生後由於系統有設計良好的備援措施,因此會進行保護性的資料存檔或歸位,這就是為什麼在圖一的「停機」前會有BKP錯誤的圖出現(這是代表在停機前所出現的所有錯誤),在「停機」後會有Workflow錯誤的圖出現(這是代表在停機後,還可進行工作流程的程序,這個程序也包括人為作業流程的程序,一直到該工作流程的程序也停止為止),附帶說明,在圖一上表示災難發生點後的BKP錯誤 ⭢ 主機錯誤 ⭢ Workflow錯誤的順序並不代表這些錯誤一定是這樣順序發生,這三大錯誤只是表示災難發生的最主要三種代表性的災難。
從以上的說明就可以知道,在災難重建的程序中,RTO作業講的是在災難重建後,可以被確認並進行災難重建程序的最短時間是多少?此部分的程序與時間的確認性是很高的,而WRT的不可確定因素,包括所花費的時程也是不容易被預估或掌控。
所以對於非常重要的系統,例如:股票交易系統、線上購物系統…等,如果有一筆上千萬的交易發生在災難發生後的瞬間,在災難重建時,你會不會希望將這筆交易資料重建回來?可是RTO的災難重建程序是無法將此交易資料重建回來。
因此WRT的評估在對重要性很高的系統來說是很重要,也需要進行評估工作的細分,請參考圖三:
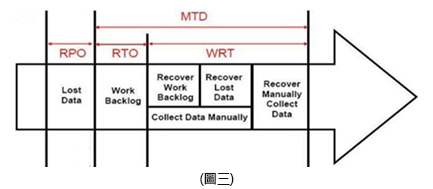
從上圖我們看到一個單字叫「Backlog」,這個英文單字常會出現在工程公司或是專案中,但翻譯成中文後便會少了許多味道,谷歌大神的翻譯是「積壓」,國家教育研究院的翻譯是「待完成量」,我比較認同後面的翻譯,因為Backlog指的是在以往(歷史)一個具有時間程序的作業,在時間程序的過程中,所進行留存下來並做為最後完成前的記錄內容稱為Backlog。
例如:在上圖三中,在RTO下的Work Backlog,指的就是將以往已經完成工作的歷史記錄進行「回存/Restore」的作業程序,這一段的作業程序是確認且可預估的,但注意到沒有,這一段並沒有使用「修復/Recover」這個單字。
而在WRT這個階段下,分成了兩大手動程序,注意了,這裡使用了「手動/Manually」,代表了這些重建程序大多是無法透過系統的自動程序來完成,而是必須透過手動或是人工的重建作業來進行。
在此階段的重建程序可以包含兩部份:第一部分稱為「Recover Work Backlog」所表示的含意是嘗試將曾經在最後備份程序失敗下,所遺留下來的記錄資料進行手動的資料修復與重建,第二部分稱為「Recover Lost Data」則是針對在完成上述程序後還是無法重建的損毀資料(一般來說,皆為暫存資料或暫存交易記錄資料)進行手動的資料修復與重建。
如果以上重建程序皆完成,依然還有損失的資料時,則會進行最後一個手動的修復與重建的階段,那就是採用人工作業流程,重新建立所需要修補的資料內容。
結論
由於篇幅的關係,本文暫時先談到此處,此部分介紹在災難重建評估上應進行的災難重建程序內容,但還沒有談完喔!因為在進行災難重建的評估上所依賴的是在還沒有發生災難前就對災難重建程序所進行的一系列維護作業,此作業便是在圖一的前半段,也就是「持續運作」評估的這一段,如有興趣,請期待下一集談論「持續運作」的相關內容喔!
待續…….

